开源数据质量解决方案 Apache Griffin入门宝典
在当今数据驱动的时代,数据质量是确保业务决策准确性和可靠性的基石。Apache Griffin作为一个开源的、强大的数据质量解决方案,在数据处理和存储服务中扮演着关键角色。本文将为您提供Apache Griffin的入门指南,涵盖其基本概念、核心功能、部署流程以及在实际数据处理场景中的应用。
Apache Griffin是一个用于大数据质量管理的开源项目,支持批处理和流式数据处理。它由Apache软件基金会孵化,专为处理大规模数据而设计,能够帮助企业和数据工程师监控、评估和提高数据质量。通过定义数据质量规则,如完整性、准确性、一致性和及时性,Griffin可以自动执行数据质量检查,生成详细的报告,并发出警报,从而确保数据在存储和处理过程中保持高标准。
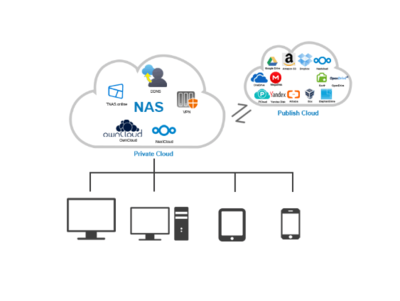
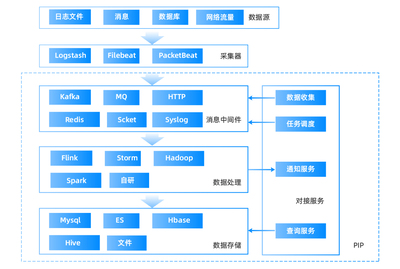
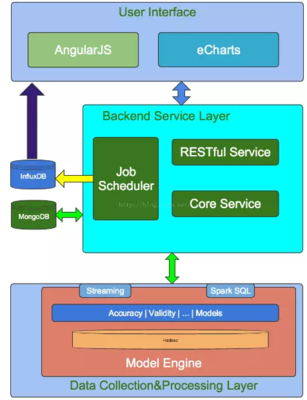
Griffin的核心组件包括数据源连接器、规则引擎和报告模块。数据源连接器支持多种数据存储系统,如HDFS、Hive、Kafka和关系型数据库,这使得它能够无缝集成到现有的数据处理流水线中。规则引擎允许用户通过简单的配置定义数据质量维度,例如数据范围、唯一性约束或模式验证。报告模块则提供可视化界面,展示数据质量得分和趋势分析,帮助用户快速识别问题。
部署Apache Griffin通常涉及几个关键步骤:准备环境,确保安装Java、Hadoop和Spark等依赖项;下载并配置Griffin发行版;然后,定义数据源和质量规则;启动服务并监控结果。为了简化入门,您可以从官方文档中获取详细的安装指南和示例配置。在实际应用中,Griffin可以应用于多种数据处理场景,例如ETL流程中的数据验证、实时数据流的质量监控,以及数据湖中的数据治理。通过定期运行质量检查,您可以及早发现数据异常,避免下游分析的错误。
Apache Griffin是一个灵活且高效的工具,适用于任何需要提升数据质量的场景。通过本入门宝典,您已经了解了其基本概念和部署流程。建议进一步探索官方社区和案例研究,以充分利用其在数据处理和存储服务中的潜力。记住,高质量的数据是成功数据战略的核心,Apache Griffin正是实现这一目标的有力助手。
如若转载,请注明出处:http://www.somaodata.com/product/31.html
更新时间:2025-11-28 12:24:32