数据科学入门系列课程(二) 数据存储与计算——流程、选型与架构演进
在数据科学的实践中,数据存储与计算是构建分析管道和实现业务价值的基石。本课程将深入探讨从原始数据到可用洞见的整体流程,并解析其中的核心概念、技术选型与主流架构。
一、整体流程与核心概念
一个标准的数据处理与存储流程通常包含以下关键阶段:
- 数据采集与接入:从各类源头(如业务数据库、日志文件、IoT设备、第三方API)实时或批量地获取数据。
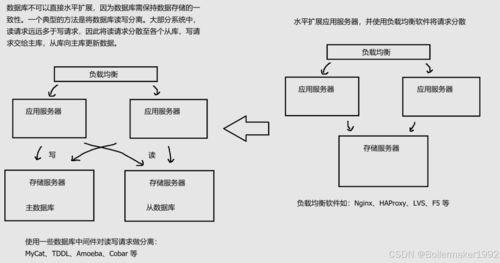
- 数据存储:将采集到的原始数据持久化保存。根据访问模式(随机读写、顺序扫描)和数据结构(结构化、半结构化、非结构化),选择不同的存储系统。
- 数据处理与计算:对存储的数据进行清洗、转换、聚合与分析。这既包括对历史数据的批量处理(Batch Processing),也包括对实时数据流的即时计算(Stream Processing)。
- 数据服务与应用:将处理后的结果数据,以API、数据仓库、数据集市或可视化报表等形式,提供给下游的业务系统、分析师或决策者使用。
理解“数据湖”(存储原始、未经加工的各种格式数据)与“数据仓库”(存储经过清洗、建模、服务于分析的结构化数据)的区别与联系,是掌握现代数据架构的关键。
二、数据库的选型:没有银弹,只有合适之选
面对琳琅满目的数据库(SQL, NoSQL, NewSQL),选型需基于业务场景和技术需求综合考量:
- 关系型数据库 (RDBMS/SQL):如MySQL, PostgreSQL。适用于事务处理(OLTP),需要强一致性、复杂查询和事务支持(ACID)的场景。
- NoSQL数据库:根据数据模型进一步细分:
- 键值存储:如Redis, DynamoDB。适用于缓存、会话存储等简单快速查询场景。
- 文档数据库:如MongoDB, Couchbase。存储灵活的JSON/BSON文档,适用于内容管理、用户档案等半结构化数据。
- 宽列存储:如Cassandra, HBase。适合海量数据的可扩展存储,常用于时间序列、物联网数据。
- 图数据库:如Neo4j。擅长处理高度互联的关系数据,如社交网络、推荐系统。
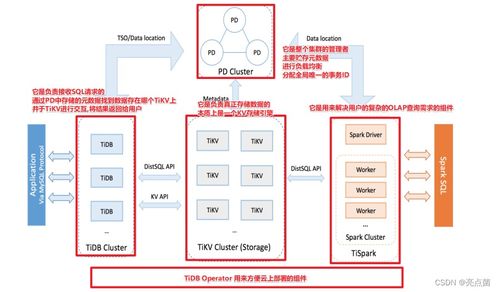
- 数据仓库与OLAP数据库:如Snowflake, Amazon Redshift, ClickHouse。专为复杂分析查询(OLAP)优化,支持对海量历史数据的快速聚合分析。
- 搜索引擎:如Elasticsearch。专为全文检索和日志分析设计。
选型核心考量点:数据模型、读写模式(吞吐量、延迟)、一致性要求、扩展性、生态工具链及总体拥有成本。
三、数据处理架构:Lambda vs. Kappa
为了同时满足对历史数据的深度分析和实时数据的低延迟响应,两种主流的混合处理架构应运而生。
1. Lambda 架构
这是一种将批处理与流处理并行、结果进行合并的经典架构。它包含三层:
- 批处理层 (Batch Layer):使用如Hadoop MapReduce, Spark等框架处理全量历史数据,生成精准但高延迟的“批处理视图”。
- 速度层 (Speed Layer):使用如Flink, Storm, Spark Streaming等流处理框架处理实时数据,生成快速但可能近似的“实时视图”,以弥补批处理层的延迟。
- 服务层 (Serving Layer):合并批处理视图和实时视图,对外提供统一的数据查询服务,如Druid或Cassandra。
优点:平衡了精度与延迟,容错性好。
缺点:系统复杂,需要维护两套逻辑相似的代码和计算管道,维护成本高。
2. Kappa 架构
作为Lambda架构的简化与演进,Kappa架构提出了一个核心思想:用一套流处理系统处理所有数据。
- 所有数据(无论历史还是实时)都被视为流(Stream)。
- 历史数据通过重新播放(Replay)事件日志(如Kafka)到流处理作业中来进行重新计算。
- 流处理系统(如Apache Flink, Kafka Streams)需要具备强大的状态管理和精确一次(Exactly-Once)处理语义。
优点:架构大大简化,只需维护一套代码;实时性更好;概念统一。
缺点:对消息队列的存储能力和流处理引擎的重播、状态管理能力要求极高;处理超长周期(如数年)的历史全量重计算时,资源消耗可能较大。
四、数据处理与存储服务:拥抱云原生
现代数据平台越来越多地采用托管服务来降低运维复杂度:
- 存储服务:对象存储(如AWS S3, Azure Blob Storage)已成为数据湖的事实标准;云托管数据库(如RDS, Cosmos DB, Bigtable)提供了开箱即用的可扩展性。
- 计算服务:无服务器计算(如AWS Lambda, Azure Functions)用于事件驱动的轻量处理;托管Spark/Flink服务(如Databricks, AWS EMR)简化了大数据集群管理。
- 一体化平台:如Snowflake(存储与计算分离的云数仓)、Google BigQuery(Serverless数仓)、Azure Synapse Analytics(统一分析服务),将存储、计算、管理高度集成。
###
数据存储与计算的选择是一场在一致性、可用性、扩展性、实时性与成本之间的持续权衡。理解从Lambda到Kappa的架构演进,反映了行业从“两套系统并存”到“统一流式优先”的思维转变。作为数据科学家或工程师,掌握这些核心概念与选型逻辑,将帮助您设计出更贴合业务需求、更高效且易于维护的数据管道,从而为数据驱动决策奠定坚实的技术基础。
如若转载,请注明出处:http://www.somaodata.com/product/51.html
更新时间:2026-01-13 02:52:31