理解JVM运行时数据区 变量存储位置与作用域的数据处理与存储服务
Java虚拟机(JVM)是Java程序运行的基石,其运行时数据区是程序执行过程中数据存储和管理的核心区域。深入理解运行时数据区,特别是变量的存储位置和作用域,对于编写高效、稳定的Java程序至关重要。本文将系统解析JVM运行时数据区,并探讨其作为数据处理与存储服务的角色。
一、JVM运行时数据区概览
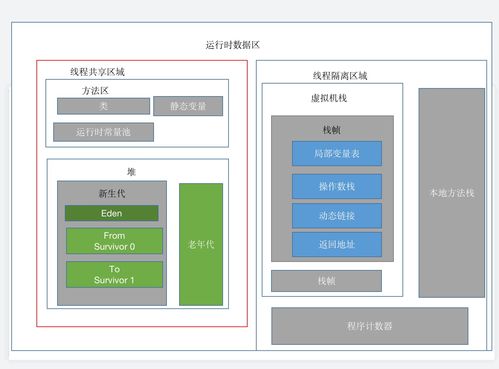
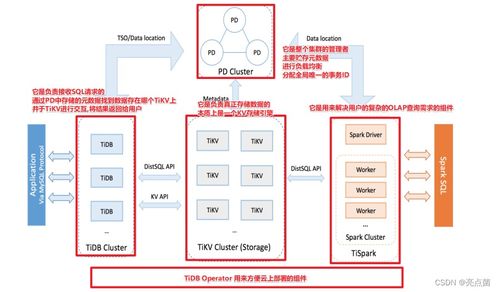
JVM运行时数据区主要分为线程私有和线程共享两大部分。线程私有区域包括程序计数器、Java虚拟机栈和本地方法栈;线程共享区域包括堆和方法区(在JDK 8及以后,方法区的部分功能由元空间实现)。这些区域协同工作,负责存储程序运行时的各类数据。
二、变量存储位置详解
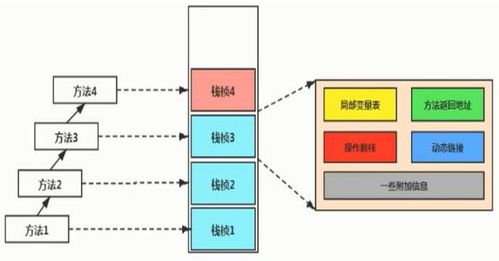
- 局部变量:存储在Java虚拟机栈的栈帧中。每个方法调用时,JVM会创建一个栈帧,用于存储局部变量表、操作数栈等信息。局部变量包括基本数据类型和对象引用,其生命周期与方法调用同步,方法结束时栈帧销毁,局部变量也随之释放。
- 实例变量(成员变量):存储在堆中的对象实例内。当通过
new关键字创建对象时,实例变量随对象分配在堆中,其生命周期与对象一致,由垃圾回收器管理。
- 静态变量:存储在方法区(或元空间)中。静态变量属于类而非实例,在类加载时初始化,生命周期贯穿整个程序运行,通常由JVM在卸载类时释放。
- 基本数据类型与引用类型:基本数据类型(如int、double)的值直接存储在栈或堆中(取决于变量类型),而引用类型变量存储的是对象在堆中的地址,通过引用访问实际对象。
三、变量作用域与数据处理
- 局部变量作用域:仅限于声明它的方法或代码块内。栈帧的隔离性保证了局部变量的线程安全,但需注意避免内存泄漏(如长时间持有大对象的引用)。
- 实例变量作用域:与对象实例绑定,通过对象访问。堆的共享特性使得实例变量可能被多个线程访问,需通过同步机制确保线程安全。
- 静态变量作用域:全局可见,属于类级别。方法区的共享性要求静态变量在多线程环境下谨慎处理,避免竞态条件。
从数据处理角度看,JVM运行时数据区提供了分层存储服务:栈负责短期、高速的局部数据,堆负责长期、动态的对象数据,方法区负责元数据和静态数据。这种设计平衡了性能与灵活性,类似现代数据处理系统中的缓存(栈)与主存储(堆)分层架构。
四、运行时数据区作为存储服务的实践意义
- 性能优化:理解存储位置有助于减少不必要的对象创建(如避免在循环中new对象),合理使用栈内存提升访问速度。例如,优先使用局部变量而非静态变量,可以减少内存冲突。
- 内存管理:通过监控堆栈使用情况,预防
StackOverflowError(栈溢出)和OutOfMemoryError(堆溢出)。例如,递归调用过深可能导致栈溢出,而大量对象堆积可能引发堆溢出。
- 并发编程:共享区域(堆、方法区)的数据需通过锁、volatile关键字等机制保证可见性与原子性,而线程私有区域(栈)天然隔离,简化了并发设计。
- 调试与调优:借助JVM工具(如jvisualvm)分析内存快照,识别内存泄漏或无效引用。例如,静态集合类不当使用可能导致方法区内存累积。
五、
JVM运行时数据区不仅是Java程序的数据存储后台,更是一个高效的数据处理与存储服务系统。通过明确变量的存储位置(栈、堆、方法区)和作用域(局部、实例、静态),开发者可以更精准地控制数据生命周期,优化内存使用,提升程序性能。在实际开发中,结合JVM监控工具和垃圾回收策略,将运行时数据区的知识应用于系统设计,能够构建出更健壮、可扩展的Java应用。
在分布式和大数据时代,这种对底层存储服务的理解,也有助于类比理解分布式缓存、数据库分片等架构思想,体现了计算机科学中“局部性原理”和“分层存储”的普遍适用性。
如若转载,请注明出处:http://www.somaodata.com/product/58.html
更新时间:2026-01-13 16:48:07