数据库集群方案 构建高可用、高性能的数据处理与存储服务
在当今数据驱动的时代,数据处理和存储服务的稳定性、性能与可扩展性已成为企业核心竞争力的关键。单一数据库实例往往难以应对海量数据、高并发访问及业务连续性的严苛要求。因此,设计一套稳健的数据库集群方案,是实现高效、可靠数据处理与存储服务的基石。本文将深入探讨数据库集群的核心架构设计,旨在为企业构建强大的数据后台提供清晰蓝图。
一、 数据库集群的核心目标与价值
一个优秀的数据库集群方案,旨在实现以下核心目标:
- 高可用性:通过冗余设计,确保在单点甚至多点故障时,服务不中断或能在极短时间内恢复,保障业务7x24小时连续运行。
- 高性能与可扩展性:通过负载均衡和分片技术,分散读写压力,支持业务和数据量的线性增长,满足高并发、低延迟的访问需求。
- 数据安全与一致性:确保数据在多个节点间可靠同步,在提供高可用的维持强一致性或最终一致性,防止数据丢失与冲突。
- 可维护性与成本效益:方案应便于监控、扩容、备份与故障切换,并在满足业务需求的前提下,优化硬件与软件成本。
二、 主流数据库集群架构模式
根据数据处理与存储的不同需求,常见的集群架构模式主要有以下几种:
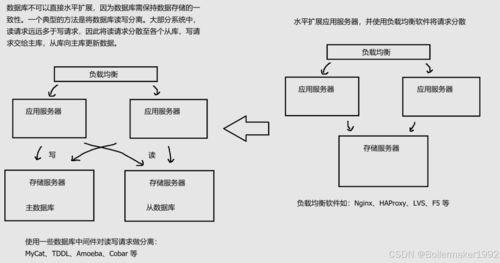
- 主从复制(Master-Slave Replication)集群:
- 架构:一个主节点负责处理所有写操作和部分读操作,多个从节点通过复制机制(如MySQL的binlog,PostgreSQL的WAL)同步主节点数据,并承担读请求。
- 数据处理:写操作集中在主节点,保证了写一致性;读操作可分流至从节点,大幅提升读性能。
- 适用场景:读多写少、对读性能要求高、可容忍短暂数据延迟(主从同步存在毫秒级延迟)的业务,如报表查询、内容分发等。
- 双主/多主复制(Multi-Master Replication)集群:
- 架构:多个节点均可独立处理读写请求,并通过双向复制保持数据同步。
- 数据处理:提升了写操作的可用性和分散性,但数据冲突解决(Conflict Resolution)机制复杂,对应用设计挑战较大。
- 适用场景:需要多地域写入、且能妥善处理冲突的业务场景,或作为高可用切换方案的一部分。
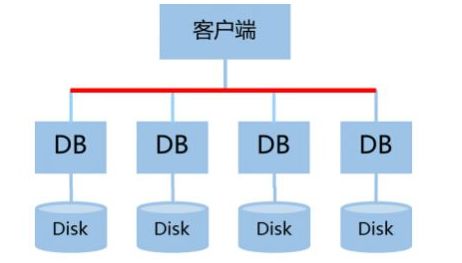
- 分片(Sharding)集群:
- 架构:将数据集水平切分为多个独立的分片,每个分片存储在不同的数据库节点/实例上。请求通过分片键路由到特定分片。
- 数据处理与存储:实现了存储和访问压力的水平扩展,是处理海量数据(TB/PB级)的核心方案。每个分片内部通常仍采用主从复制保证其自身的高可用。
- 适用场景:数据量巨大,单一节点无法存储或性能成为瓶颈的场景。如大型电商平台、社交网络的核心业务数据。
- 基于共享存储的集群(如Oracle RAC):
- 架构:多个计算节点共享同一份存储(如SAN),所有节点可同时读写数据,通过缓存融合技术协调内存数据。
- 数据处理:提供了极佳的高可用性和扩展性,但架构复杂,对硬件(特别是存储网络)要求高,成本昂贵。
- 适用场景:对可用性和性能有极高要求,且预算充足的企业关键应用(如金融核心交易系统)。
三、 构建数据处理与存储服务的关键考量
在设计集群方案时,需从服务整体视角进行系统化思考:
- 读写分离与负载均衡:在应用层或中间件(如ProxySQL, MaxScale, ShardingSphere-Proxy)层实现读写请求的智能路由,将写请求定向至主节点,读请求均匀分配至健康的从节点。
- 故障自动切换(Failover):通过集群管理组件(如MHA for MySQL, Patroni for PostgreSQL, Sentinel for Redis)监控节点健康状态,在主节点故障时,能自动或半自动地将一个从节点提升为新主,并更新路由信息,实现快速故障恢复。
- 数据同步与一致性权衡:根据业务容忍度选择同步复制(强一致,性能影响大)或异步/半同步复制(更高性能,存在数据丢失风险)。在分布式场景下,需深入理解CAP定理,在一致性、可用性、分区容忍性之间做出合理取舍。
- 监控与运维体系:建立全面的监控指标(如节点状态、复制延迟、QPS/TPS、连接数、慢查询),配合告警机制。制定规范的备份、扩容、数据迁移流程,确保集群长期稳定运行。
- 安全性设计:确保集群内节点间通信加密,实施严格的网络隔离与访问控制策略,定期进行安全审计与漏洞扫描。
四、 技术选型与实践建议
- 开源方案组合:对于大多数互联网业务,可采用成熟的MySQL/PostgreSQL主从+分片,配合Redis Cluster(缓存)和Elasticsearch集群(搜索),形成混合数据服务栈。中间件可选MyCAT、ShardingSphere或Vitess(用于MySQL)。
- 云数据库服务:直接采用云厂商提供的托管数据库服务(如AWS Aurora, RDS; Azure Database; 阿里云PolarDB, RDS),能极大降低运维复杂度,内置高可用、备份、监控等功能,是快速上线的优选。
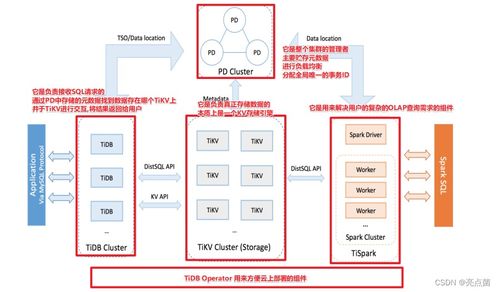
- NewSQL数据库:对于需要强一致性且规模不断增长的业务,可考虑TiDB、CockroachDB等NewSQL数据库,它们原生支持分布式、高可用和HTAP(混合事务/分析处理)。
###
数据库集群方案的设计没有银弹,它是一个权衡的艺术。成功的架构始于对业务需求(数据规模、访问模式、一致性要求、SLA等级)的深刻理解,成于对技术组件的娴熟选型与有机整合,并最终依赖于完善的监控与运维实践。构建一个健壮的数据处理和存储服务,不仅是技术能力的体现,更是保障业务持续创新与稳定增长的坚实底座。从规划之初,就应将可扩展性、可靠性和可运维性作为核心设计原则,从而从容应对未来的数据挑战。
如若转载,请注明出处:http://www.somaodata.com/product/52.html
更新时间:2026-01-13 11:38:09